
Real-Time Analytics Plattform
Mit unserer ,,Real-Time Analytics“ Plattform bieten wir Ihnen eine Lösung, mit der Sie Ihre Daten in Echtzeit als Streams empfangen, bearbeiten und analysieren können. Zusammen mit der IoT-Lösung von AWS kann unsere Plattform eine Mehrzahl an Streams von Sensorendaten, Services , Social Media usw. abdecken.
In der Plattform haben wir führende Technologien wie Mesos, Kafka, Cassandra und Spark-Streaming integriert, die auch aufeinander abgestimmt sind und bauen auf Industriestandards wie Java auf. Damit haben Sie auch Support und Entwicklungssicherheit und profitieren von den neuen Entwicklungen.
Da wir die Plattform in Ihrer ,,Private Cloud“ implementieren, haben Sie die vollständige Kontrolle über Ihre Daten und hohe Flexibilität über Ihre Prozesse. Dennoch nutzen Sie die Vorteile einer Cloud basierten Lösung wie geringe Investitionskosten, hohe Skalierbarkeit, maximale Mobilität und verbrauchsbasierten Gebühren.
Cassandra ist eine der führenden verteilten und hochverfügbaren No-SQL Datenbanken, die bei namhaften Unternehmen u.a. Cisco, Credit Suisse, Disney, Ebay, Hp uvm. im Betrieb ist.
Cassandra ist bekannt für Hochverfügbarkeit und Hochdurchsatz -Eigenschaften und sie ist in der Lage, enorme Schreiblasten zu handhaben und Cluster-Knoten Ausfälle zu überstehen. In Bezug auf das CAP-Theorem bietet Cassandra eine konfigurierbare Konsistenz und Verfügbarkeit für den Betrieb.
Im Hinblick auf die Datenverarbeitung ist Cassandra linear skalierbar (erhöhte Belastungen können durch Erhöhung der Anzahl der Knoten eines Clusters abgedeckt werden) und sie ist in der Lage, Cross-Rechenzentrum Replikation (XDCR) durchzuführen. XDCR bietet eine Reihe von interessanten Anwendungsfälle für:
- geo-verteilte Rechenzentren: Daten, die spezifisch für die Region sind oder näher an den Kunden liegen.
- Datenmigration in Rechenzentren: Wiederherstellung nach Ausfällen oder Verschieben von Daten auf einen neuen Datacenter.
- getrennte Betriebs- und Analytik-Workloads: Es können getrennte Cluster für schreib-intensive und analyse-intensive Anwendungen aufgesetzt werden.
Cassandra unterliegt der Apache 2.0 Lizenz.
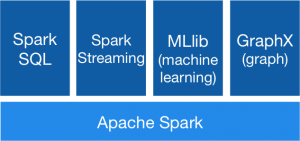
Spark ist eine sehr schnelle Engine für verteilte, groß angelegte Datenverarbeitung und wird heute als quasi Standard in den meisten Plattformen (SAP, Microsoft, IBM usw.) für Big-Data Analytics verwendet.
Dabei wird nach dem „Map-Reduce“ Prinzip die Datenverarbeitungsaufgabe vom Spark-Master in mehrere Teile zerlegt und an die verteilten Maschinen (sog. Worker) verschickt. Diese arbeiten die Teilaufgaben ab und senden die Ergebnisse an den Master, der die Teilergebnisse zu einem Gesamtergebnis zusammenfügt. Ein Spark-Cluster kann dabei aus einer Vielzahl (Je nach Anforderungen) von verteilten Maschinen (sog. Worker) bestehen
Spark hat die führende Technologie der letzten Jahren ,,Hadoop MapReduce“ abgelöst und führt die Programme bis zu 100x schneller als ,Hadoop MapReduce im Speicher (In Memory) oder 10x schneller auf dem Datenträger aus. Darüber hinaus ist die Handhabung einfacher, die Programmierung effizienter und die Module für verschiedene Analytics-Aufgaben sind bereits in Spark integriert.
Cassandra unterliegt der Apache 2.0 Lizenz.
Kafka ist ein mit hohem Durchsatz und geringer Latenz verteiltes Messaging-System. Es dient als Buffer für eingehende und ausgehende Streams. Apache Kafka wird oft mit Spark genutzt, da es auf verschiedene Knoten verteilt werden kann und Schnittstellen auf den Servern bietet. Es zeichnet sich durch folgende Eigenschaften aus:
- Schnelligkeit: Ein einzelner Kafka Broker kann Hunderte von Megabytes an Lese- und Schreibvorgängen pro Sekunde durchführen.
- Skalierbarkeit: Es kann elastisch und transparent, ohne Ausfallzeiten erweitert werden.
- Ausfallsicher: Nachrichten werden auf Servern beibehalten um innerhalb des Clusters replizierten Datenverlust zu verhindern.
- Distributed by Design: Kafka hat ein modernes Cluster-zentriertes Design, das starke Haltbarkeit und Fehlertoleranz garantiert.
Cassandra unterliegt der Apache 2.0 Lizenz.
Mesos ist ein Cluster-Ressource-Management-System, das eine effiziente Ressourcen Freigabe und Isolation in verteilten Anwendungen oder Frameworks“ bietet. Da die verteilten Server als ein System betrachtet werden, können die Ressourcen effizienter genutzt werden, da sie nach Bedarf zugewiesen werden.
Mit der zunehmenden Anzahl von Diensten, Servern und Applikationen wird das Management und Monitoring des Systems komplexer. Mesos reduziert die Komplexität und darüber hinaus erleichtern eingebauten Dienste wie Marathon die fehlertolerante Ausführung von Applikationen mit langer Laufzeit. Dies ist insbesondere für Streaming-Real-Time Dienste wichtig.
Mesos unterstützt nativ Spark, Kafka und Cassandra und zeichnet sich durch hohe Benutzerfreundlichkeit aus. Mesos ist bei namhaften Unternehmen wie Apple, Ebay, Verizon usw. in Betrieb.
Cassandra unterliegt der Apache 2.0 Lizenz.
AWS IoT bietet eine sichere, bidirektionale Kommunikation zwischen mit dem Internet verbundenen Dingen (wie Sensoren, Aktoren, eingebettete Geräte oder intelligente Geräte) und der AWS-Cloud. Auf diese Weise können Sie Telemetriedaten von mehreren Geräten sammeln, speichern und die Daten analysieren. Sie können auch Anwendungen erstellen, die den Benutzern ermöglichen, diese Geräte von ihren Handys oder Tabletts zu steuern.
Unsere Plattform nutzt AWS IoT insbesondere aufgrund von Sicherheitsanforderungen.
Mit EM-Streaming-Server können sie Web-Socket Streams empfangen und an Kafka weiterleiten sowie Messages von Kafka empfangen und als Web-Sockets Streams an Web-Client weiterleiten. Unsere Lösung läuft auf der ,,Java Virtual Machine“ und zeichnet sich durch Schnelligkeit und Belastbarkeit aus . Darüber hinaus bieten wir Real-Time Web Lösungen an, in denen die Daten in Echtzeit visualisiert werden können.
Der EM-Streaming-Server wird individuell, entsprechend Ihren Anforderungen, konfiguriert und die Streaming Schnittstellen sowie die Web-Anwendung programmiert.
Real-Time Processing
Streaming-Daten sind Daten, die kontinuierlich und aus einer Vielzahl von Datenquellen generiert werden. Die Datenaufzeichnungen werden im Regelfall simultan und in kleinen Paketen (Kilobyte-Bereich) verschickt. Diese Daten müssen sequentiell und inkrementell auf Aufzeichnungsbasis oder in gleitenden Zeitfenstern verarbeitet werden. Beispiele für Streaming-Daten sind
- Sensoren von Industrieanlagen und Maschinen senden Daten an eine Real-Time Anwendung zur Überwachung der Produktion.
- Ein Finanzunternehmen überwacht die Finanztranskation in Echtzeit auf Anomalitäten und Betrugsfälle.
- Auswertung der Börsenentwicklung und Aktienentwicklung anhand Extra Echtzeitdaten.
- Online-Shop wertet die Besucheraktivität und die Anzahl der Clicks in Echtzeit aus.
- Eine Mobilanwendung für Immobilien sendet den Anwendern, basierend auf ihrem Standort, Vorschläge für potentielle Objekte zur Besichtigung in der Nähe zu.
Anders als bei Batch-Verarbeitung, liegt die erforderliche Latenz bei Stream-Verarbeitung im Bereich von Sekunden oder Millisekunden. Diese stellt besondere Anforderung sowohl auf die Verarbeitung als auch auf die Speicherung der Daten. Darüber hinaus muss das System ausfallsicher und skalierbar sein.
Unsere ,,Real-Time Analytics“ Plattform ist auf die Anforderungen ausgelegt und stellt sicher dass die Streaming-Daten in der erforderlichen Latenz bearbeitet werden. Mit Kafka, Spark und Cassandra bauen wir auf Technologien, die sich in vielen anspruchsvollen Echtzeit-Anwendungen bereits bewährt haben.